Moving Averages
When averaging time-series data, you often want to smooth out peaks and valleys. A moving average is an easy way to smooth your data. When I track my weight, for example, I use a 7-day moving average. This smooths out peaks associated with weekends when I might go out to eat and enjoy a beer or two.
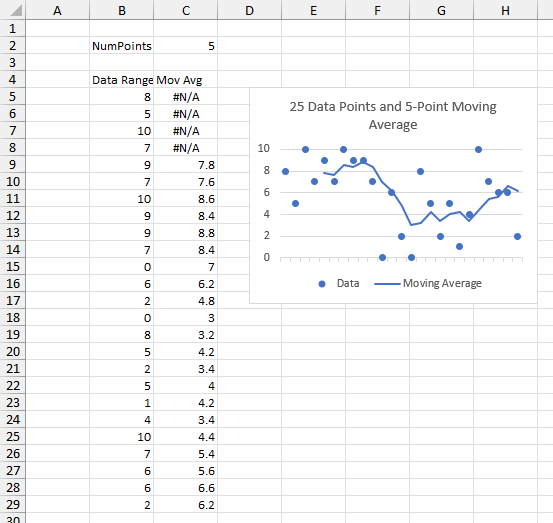
The image below shows 25 random data points and a five-point moving average. The points were generated with this Dynamic Array formula in cell B5:
=RANDARRAY(25,,0,10,TRUE)
and the moving average was calculated with this formula in cell C5, filled down to C29:
=IF( COUNT(OFFSET($B5,0,0,-$C$2,1))=$C$2, AVERAGE(OFFSET($B5,0,0,-$C$2,1)), NA() )
When building large, complicated LAMBDA formulas, it has become common to enhance the readability of the formulas with line feeds (use Alt+Enter to insert a line feed in the Formula Bar) and spaces. I find it helps with older formulas as well.
This moving average formula needs to be placed in each row of the moving average range. If it’s in a Table, that’s no big deal, because adding more data will automatically fill the formula into added Table rows.
But the data was the result of a Dynamic Array formula in just cell B5, and the output spilled down as far as the formula required. It would be nice to build a Dynamic Array formula for moving average which is written just in cell C5 but spills down as far as the Dynamic Array it averages.
There are many formulas you can use to calculate a moving average, using variations of INDEX and OFFSET formulas. Incidentally, if you don’t need the moving average values in the worksheet, you can use an Excel chart’s trendline feature to display the moving average.
Internet Search for Dynamic Array Moving Average
I tried my hand at writing my own formula and got stuck almost immediately. I searched Bingle to see what I could find.
I found a lot of possible answers. The ones that seemed easy didn’t work. The ones that worked were very complicated, and I really didn’t understand them very well. I finally settled on one from Lambda Moving Average – calculate rolling sum in Excel (and much more). The original version of this function included a parameter that lets you choose whether to calculate a moving average or other moving statistical functions. I cleaned out all the other functions and was left with the moving average below:
=LAMBDA(x,window,
LET(
_x, x,
_w, window,
_thk, LAMBDA(x, LAMBDA(x)),
_fn, _thk(LAMBDA(x, AVERAGE(x))),
_i, SEQUENCE(ROWS(x)),
_s, SCAN(
0,
_i,
LAMBDA(a, b, IF(b < _w, NA(), _thk(MAKEARRAY(_w, 1, LAMBDA(r, c, INDEX(_x, b - _w + r))))))
),
_out, SCAN(0, _i, LAMBDA(a, b, _fn()(INDEX(_s, b, 1)()))),
_out
)
)
As I said, it works fine, but I don’t really understand how it works. I’m reluctant to include it in a project for a client if I don’t grok it, but I’ve implemented it in some of my own workbooks. It seems to run slowly, probably because for each element of the original array, it generates a subset of that array to calculate an average. For an array with hundreds of points, that adds up to hundreds of smaller arrays.
I also went to ChatGPT to see what it could tell me. It showed me lots of code samples and several formulas that resembled Excel formulas. But many formulas had errors, and no formula that had no errors returned a moving average.
Running Sums?
I couldn’t wrap my tired, old brain around the algorithm above, but sometimes my brain gets bored, looks out the window, and surprises me with what it comes up with. And my approach isn’t rocket science, but it is less cumbersome than creating multitudes of arrays which all include partial duplicates of the original array’s values. I can calculate the running sum of the original array, subtract the running sum from an earlier row, and divide by the number of points, and I’ll have my moving averages.
First, I’ll show how it works. Here’s my data in the second column below. For reference I’ve inserted a sequence number in the first column. The gold-shaded range in the third column contains the running sum of the data in the second column. The fourth column contains the same shaded running sum, offset by 5 rows so I can compute my 5-point moving average. The first four cells of a 5-point moving average are not calculated; I’ve entered #N/A so they are not plotted.
Delta is the difference between the two running sums, that is, the intermediate moving sum, and Average is Delta divided by 5.
The first 5-point average is calculated for the 5th value, where the running sum is 39: 39 divided by 5 is 7.8.
The second calculation is for the 6th point, where the running sum is 46. But we only want the sum of points 2 through 6, so we subtract the running sum for point 1, which is 8. (46-8)/5 is 7.6. And so on.

Now let’s get it into a single formula.
Building the Formula
The following range illustrates the steps toward building the formula; several steps are just me learning how some new Excel functions work. Column B contains the original formula, and column C is my old-style formula-in-every-cell to calculate the moving average. I’ve hidden columns D:I.
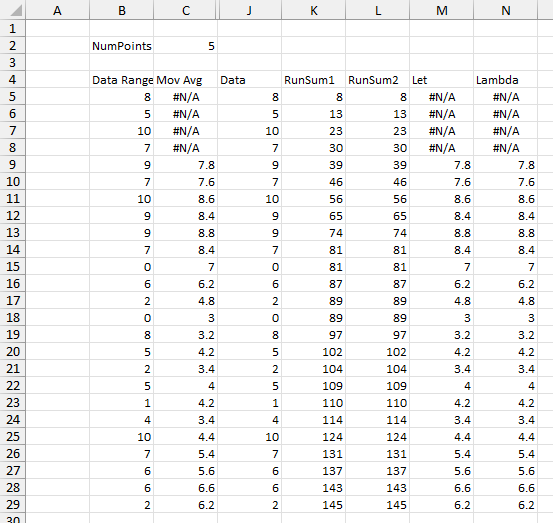
Column J spits out the original data range. This isn’t necessary in the final formula, but I was gaining confidence with BYROW. BYROW works by defining an array, passing it row by row into a LAMBDA function, and building an array of the results of that LAMBDA for each row. The array passed in is a simple SEQUENCE, from 1 to the number of rows in the original data range. Each element of the sequence is passed as x into LAMBDA, which returns the xth element of the data range.
=LET(
datarange,B5#,
BYROW(
SEQUENCE(ROWS(datarange)),
LAMBDA(x,INDEX(datarange,x))
)
)
The running sum in column K is easy to calculate with the new Dynamic Array helper functions. Like BYROW, SCAN passes each element of an array into a LAMBDA function, which calculates each element of the output array, Again, this isn’t strictly necessary, but I was learning about SCAN.
The first argument of SCAN is the starting value (zero since it’s missing), the second is the original data range. LAMBDA accepts the starting value a and the data value b then applies the function a+b to generate the output value. This output becomes the new starting value a, which is added to the next data value b, etc.
=LET( datarange,B5#, SCAN(,datarange,LAMBDA(a,b,a+b)) )
The running sum in column L is a bit more convoluted, but it’s leading to my ultimate formula. SCAN is used as above to generate the running sum, but instead of spitting it out into the worksheet, it is stored in the name runsum. Then BYROW is used to return each element of runsum.
=LET(
datarange,$B$5#,
runsum,SCAN(,datarange,LAMBDA(a,b,a+b)),
BYROW(
SEQUENCE(ROWS(datarange)),
LAMBDA(x,INDEX(runsum,x))
)
)
If I can get the xth element of runsum, I can also get the element numpoints before that and subtract it. If x is less than numpoints, this corresponds to an early point which displays #N/A. If x is equal to numpoints, it’s the first calculated value, and there is no running sum to subtract, so I subtract zero. After subtracting to get the intermediate sum, I divide by numpoints to get the average.
=LET(
datarange,$B$5#,
numpoints,$C$2,
runsum,SCAN(,datarange,LAMBDA(a,b,a+b)),
BYROW(
SEQUENCE(ROWS(datarange)),
LAMBDA(x,
IF(
x<numpoints,
NA(),
(INDEX(runsum,x)-IF(x=numpoints,0,INDEX(runsum,x-numpoints)))
/numpoints)
)
)
)
I can rewrite this as a LAMBDA:
=LAMBDA(datarange,numpoints,
LET(
runsum,SCAN(,datarange,LAMBDA(a,b,a+b)),
BYROW(
SEQUENCE(ROWS(datarange)),
LAMBDA(x,
IF(
x<numpoints,
NA(),
(INDEX(runsum,x)-IF(x=numpoints,0,INDEX(runsum,x-numpoints)))
/numpoints)
)
)
)
)($B$5#,$C$2)
Note that the LAMBDA formula above ends with ($B$5#,$C$2), which is how these arguments are entered into the formula. To make this a reusable function, copy the formula without these arguments and their parentheses. Go to Formulas tab > Define Name. Enter a function name and short description, paste the formula into the Refers To box, and press Enter.
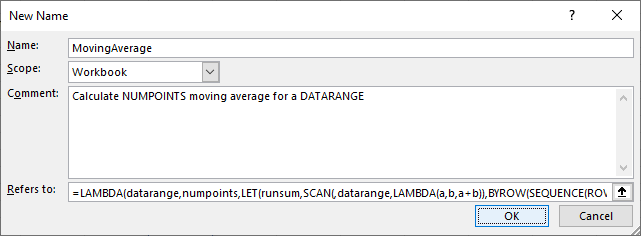
Using the Define Name method is suboptimal. The entire LAMBDA function cannot be viewed at once, and you lose the line feeds and white space. You could also use the Advanced Formula Environment, a free add-in from Microsoft.
You can now use this formula throughout the workbook using this simple syntax:
=MovingAverage(B5#,C2)
Improvements
I exchanged several comments on my earlier post with a smart reader named Henk-Jan van Well, who suggested several improvements to the moving average algorithm, starting with CHOOSEROWS, then evolving to TAKE and DROP. This led to simplified and more robust formulas, and also to a moving average by date which dealt nicely with missing dates, i.e., it averaged values within seven days rather than averaging seven consecutive values that may span more than seven days. See the improved post at Improved Excel Lambda Moving Average.
More About Dynamic Arrays, LET, and LAMBDA
- ISPRIME Lambda Function
- Lambda Moving Average Formulas
- Improved Excel Lambda Moving Average
- LAMBDA Function to Build Three-Tier Year-Quarter-Month Category Axis Labels
- Dynamic Array Histogram
- Calculate Nice Axis Scales with LET and LAMBDA
- VBA Test for New Excel Functions
- Dynamic Arrays, XLOOKUP, LET – New Excel Features


Henk-Jan van Well says
Dear Jon,
nice post and I’m quite new to these dynamic array functions in Excel as well, so the struggle is real, but quite fun, to be honest. I started my career some 30+ years back with programming in APL, which forced me to learn to think in arrays, especially arrays of indices. Based on this and my current (limited) knowledge of the dynamic array functions in Excel made me write the following moving average lambda function (copied as a single line from the name manager):
=LAMBDA(datarange,numpoints,MAKEARRAY(ROWS(datarange), , LAMBDA(r,c, IF(r < numpoints, NA(), AVERAGE(CHOOSEROWS(datarange, SEQUENCE(numpoints, , 1 + r – numpoints)))))))
The crux is the CHOOSEROWS-function using the SEQUENCE-function to select a sub-array of the original array. Please have a look and let me know what you think. Have fun!
P.S. I recall from econometric class that the first elements of a moving average series are officially not NA() but, for example when numpoints=5 then the first element would 5xthe first data point divided by 5, the second element would be (4xthe first data point + the second data point) divided by 5, the third element would be (3xthe first data point + the second data point + the third datapoint) divided by 5 etc. Which is of course (even) more challenging to implement ;-)
Jon Peltier says
Henk-Jan –
Your formula certainly works, and it’s easier to understand than the first one I cited. I hadn’t thought of CHOOSEROWS, and using that with SEQUENCE is a smart approach.
Your note about econometrics makes me think of a similar moving average: by date rather than by point. For example, if you are doing a five-day moving average, you only average the data that falls within the five-day range. If data is missing for one day, you average the four days that have data, and no points outside of the five-day range. Fpr the first point you use the value of the first day. For the second point you use the average of the first two days, if they both fall within the five-day moving range, etc. I am working on a running sum approach, using XMATCH on the date column to determine the first point of each moving calculation. But the CHOOSEROWS approach could also work.
Jon Peltier says
Henk-Jan –
I don’t like the econometric approach of counting the first point extra times until you get to the Nth point, where N is the width of the moving average. But I can get behind the first average averaging just the first value, the second averaging the first two values, etc. And I have modified your formula ever so slightly to produce this:
Henk-Jan says
Jon,
I’m perfectly fine by the “expanding” average approach up to numpoints data points and I guess you did it. Nice, well done!
Would the date variant not be similar to this approach when you make the following modifications:
1. leave dates with missing data simply in the series with value #N/A
2. replace the current average by:
i. assign the CHOOSEROWS-argument of the current average to a variable X using LET,
ii. calculate the “new” average by using AGGREGATE(9,6,X)/AGGREGATE(2,6,X), i.e. using SUM and COUNT ignoring #N/A’s
This will most probably give an error if there are consecutive dates with missing data for a period longer than numpoints, but that is not necessarily wrong as there is actually no (moving) average for such a period.
Jon Peltier says
In my data, missing data is not a blank cell in the value column, it’s a row that doesn’t appear. That is, when data is added, the date and the value are added, but if the value is not measured on a given date, no row is added. I’m using XMATCH to find the first date within the averaging range, and up to a point it’s giving me what I expect. But before I even get to CHOOSEROWS, something in my formula is not working. I’ll come back to it in a day or so.
Henk-Jan says
The AGGREGATE-approach with missing data as #N/A for each date with no data works when you built all the steps on a worksheet, similar to what you did for the regular moving average at the start of your post. The problem is however that it seems that the LAMBDA-function doesn’t like AGGREGATE (too bad). I also noticed that array-functions are no fan of randomized inputs, every now and then #SPILL-errors are returned (this behaviour is documented by Microsoft, so something to keep in mind).
Anyway, I guess I have solved calculating the MA based on dates:
MovingAverage(datarange, mapoints, [daterange])
=LET(
length, ROWS(datarange),
index, SEQUENCE(length),
MAKEARRAY(
length,
1,
LAMBDA(r, c,
LET(
subindex, CHOOSEROWS(index, SEQUENCE(MIN(r, mapoints), , MAX(1, 1 + r – mapoints))),
filter, IF(
NOT(ISOMITTED(daterange)),
LET(
subdaterange, CHOOSEROWS(
daterange,
SEQUENCE(MIN(r, mapoints), , MAX(1, 1 + r – mapoints))
),
FILTER(subindex, subdaterange > (TAKE(subdaterange, -1) – mapoints))
),
subindex
),
AVERAGE(CHOOSEROWS(datarange, filter))
)
)
)
)
Based on the previous expanding regular moving average the “trick” is to apply a similar approach to the date-range, i.e. use the (expanding) array of indices (=SEQUENCE(MIN(r, mapoints), , MAX(1, 1 + r – mapoints)) to select the subdaterange of possible past dates that fall within the MA-period. Next use this subdaterange to filter the original subindex for those dates within subdaterange that are greater than the last date in subdaterange minus the ma-period.
This formula calculates both the regular moving average and the date based moving average. If no daterange is entered (as it is optional) then the final filter for selecting the relevant data points equals the original subindex (and the regular moving average is returned), else (a daterange is entered) the final filter equals the original subindex filtered for the dates greater than the date counted back ma-points of days from the date for which the date-based moving average is calculated.
Please have a look and let me know what you think.
HJ says
I just realized the index-array and the first CHOOSEROWS are obsolete….
MovingAverage(datarange, mapoints, [daterange])
=LET(
length, ROWS(datarange),
MAKEARRAY(
length,
1,
LAMBDA(r, c,
LET(
subindex, SEQUENCE(MIN(r, mapoints), , MAX(1, 1 + r – mapoints)),
filter, IF(
NOT(ISOMITTED(daterange)),
LET(
subdaterange, CHOOSEROWS(daterange, subindex),
FILTER(subindex, subdaterange > (TAKE(subdaterange, -1) – mapoints))
),
subindex
),
AVERAGE(CHOOSEROWS(datarange, filter))
)
)
)
)
HJ says
Sorry for spamming you Jon, but this morning when I woke up I guess all my old APL-skills returned from my subconsciousness…
Although using CHOOSEROWS with SEQUENCE is a smart approach, there is even a smarter way using DROP and TAKE to select a (dynamic) part of an array. DROP and TAKE are basically the array-equivalents of what LEFT and RIGHT are for strings. Using these functions you can directly select a sub-part of an array without having to construct first the array of sub-indices to select the sub-part of interest. Have a look at the even shorter implementation of moving average below, which is of course called shorter too: MovAvg ;-)
MovAvg(datarange,mapoints,[daterange])=MAKEARRAY(
ROWS(datarange),
1,
LAMBDA(r, c,
LET(
subdatarange, DROP(TAKE(datarange, r), MAX(0, r - mapoints)),
finaldatarange, IF(
NOT(ISOMITTED(daterange)),
LET(
subdaterange, DROP(TAKE(daterange, r), MAX(0, r - mapoints)),
FILTER(subdatarange, subdaterange > (TAKE(subdaterange, -1) - mapoints))
),
subdatarange
),
AVERAGE(finaldatarange)
)
)
)
Jon Peltier says
Henk-Jan –
Thanks so much! TAKE and DROP makes this calculation so much easier. In about fifteen minutes I streamlined my MovingAverageByPoints LAMBDA and finally wrote a MovingAverageByDates LAMBDA.
I’ll write a follow-up post to describe these improved functions.
HJ says
Jon,
You’re most welcome. TAKE and DROP are great for selecting parts of arrays without having to define explicitly the underlying indices of the parts you want. You can even apply them to mxn arrays as well. They have some overlap in functionality with CHOOSEROWS and CHOOSECOLUMNS, although there you have to know the exact indices of the parts you want. The latter two are better suited to select repetitively the same row(s)/column(s) from an array, or if you want to change the order of rows/columns within an array.
Looking at your solutions compared to mine I notice that in the date based version you explicitly look for the first date within the moving average period to select the points of interest. In my solution this first date is implicitly in the filter condition: subdaterange > (TAKE(subdaterange, -1) – mapoints). The filter condition returns a boolean array of length mapoints of TRUE/FALSE-values. The first date matches exactly the first TRUE in this boolean filter array. Note that TAKE(subdaterange, -1) returns the last element of the array subdaterange, which matches by construction the date corresponding to the r-index, i.e. the date for which the MA is being calculated. So no surprise both functions give the same results!
In the meantime I posted my implementation on LinkedIn, of course with all credits to you for this fun problem. Let me know when you have a new challenge ;-) Best, HJ
Meni Porat says
Hi Jon,
I adapted your formula/LAMBDA from “Moving Average” to “Moving Sum” with a very slight modification to your formula.
Thank you
Jon Peltier says
Hi Meni –
That would not be a difficult adjustment. Glad you could take advantage of my formula.