In Daily Chart: Tax the Rich to Pay For Health Care? Conor Clarke responded to a proposal to pay for health care reform by taxing the rich. He plotted the variation in the effective Federal tax rate paid by the top 1% of households to put into perspective the effect of a few additional percent added to the taxes of these high earners. I have downloaded the data from the Congressional Budget Office web site and reproduced Clarke’s chart below.
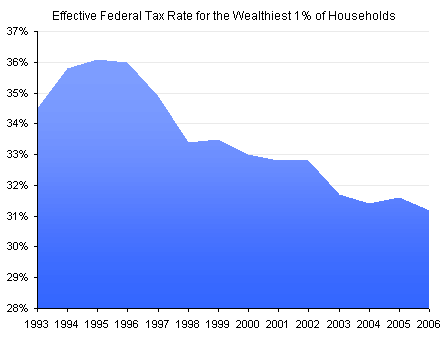
In Stupid Chart of the Day, James Joyner points out that Clarke’s chart starts from 28%, not from 0%, and thus it is deceiving. (I don’t think it’s really that stupid a chart, but maybe Joyner is going for more pageviews.) In Charts can be Deceiving E.D. Kain followed up on this observation, and produced his own chart of the data; I have reproduced Kain’s chart below.

So which chart is right, and which is deceiving? Well, both plot the data correctly, in terms of not using wrong data. But both have built-in flaws which distort the reader’s interpretations.
Using an axis that starts from zero is important in bar (and column) charts, because the visible length of the bars is what the reader sees and relates to the values. If the bars are truncated, their true length cannot be known, and the user is misled. Since the region under the line of an area chart is shaded, it implies that the area is the important encoding feature in the chart. Thus, starting the axis above zero is misleading for area charts as well as for bar charts.
I don’t think Clarke was attempting to mislead. When you enter his data into Excel and draw an area chart, Excel decides to start the axis at 28% by default, and Clarke simply made no attempt to change the default axis scale. (He did adjust the default fill by introducing a gradient, but the judges are not concerned with artistic impression here.)
And what of Kain’s chart? How is that chart deceptive? Let’s ignore the irrelevant two decimal digits he has added to his Y axis labels. Kain has started his Y axis at 0%, according to best practices for bar (and area) charts. He has made the Y axis maximum 100%, however, which compresses the data into the bottom portion of the chart. The variability in the data is dwarfed by the magnitude of the Y axis.
In any case, a line (or XY/scatter) chart has no implicit requirement to start at zero, since the position of the data points is what encodes their value.The benefit of using a line chart is that you can match the Y axis scale so that it spans from a little bit below the lowest data point to a little bit above the highest.
The 28% default minimum assigned by Excel isn’t even far enough from zero. I’ve used a minimum of 30% and a maximum of 37% on the Y axis of my line chart. This shows the steady decline in tax rate since the mid-1990s, but in no way implies that the tax rate now is 1/6 of it’s peak value.



jeff weir says
I think there’s more deciet in plotting this one series in isolation from tax rates for other groups. It would have been interesting had they compared what was going on in say the varies quintiles in the data source.
That said, it’s all relative to how far above the poverty line you are, I suppose. So according to some branches of social policy thought, it might not make sense to compare these all equally from a pure numeric perspective.
It’s worth noting that we’re talking about ‘effective’ tax rates and not actual ones… Effective rates are calculated by dividing tax revenue by comprehensive household income – i.e. federal taxes paid as a percentage of household income. So we probably don’t have enough data here to say “This shows the steady decline in tax rate since the mid-1990s”…you really need to use the phrase ‘effective tax rate’ in there, because the actual tax rate for a group may have remained the same (or even gone up), whereas at the same time householders imay have gotten smarter about how to reduce their tax obligations as a group, or their income as a group may have risen compared with other groups.
Where Clarke says “Even a 3% increase across the board will leave an effective rate lower than it was in 1995”, he’s suggesting that a 3% increase in the actual tax rate should result in a 3% increase in the effective tax rate. I doubt that would happen…because consumers tend to change their behavior in responce to tax increases, not carry on as they were regardless. I would expect effective taxes for this group to increase, but not by 3%. Conversely, I would not expect tax revenue from this group to suddenly jump by 3%.
E.D. Kain says
Oh absolutely my graph was deceiving as well – that was actually my point: that depending on how one draws these things makes all the difference, and that unless you are very careful (and sometimes even then) they are better at creating illusions than conveying data.
Mike Alexander says
Excellent post Jon. One always hears admonitions about not starting the Y axis at 0, but no one ever points out the importance of the Y axis Maximum.
This is an fantastic example of how the Y axis maximum can distort data.
Gary says
I’d have to say that Kain’s chart is more deceptive. The other deception may be in starting the process in 1993 – the dataset goes back to 1979 and tells a broader tale.
Agree entirely that comparing highest-percentile to other percentiles is one of the important contexts for this. With that in mind:
Excel 2007 charts don’t suck as much as Excel <=2003, I have to say. Not much polishing required.
Jon Peltier says
Erik – “How to Lie with Statistics” and ‘How to Lie with Charts”?
Jon Peltier says
Gary –
Some of the default formatting for 2007 charts might be better than that in 2003 charts. But…
The user interface for working with charts in 2007 is so awkward, that creating charts and fixing chart formatting in 2003 is far easier than creating and fixing charts in 2007. If I want to format a line chart series in 2003, I need to visit one dialog tab, and I can then select another chart series, hit F4, and apply the changes to another series. To format that same line chart series in 2007, I may need to visit up to SIX dialog tabs, and the F4 (Repeat Last Action) key has been eviscerated.
Gary says
As I found out while constructing this:
which probably got lost in the original comment. Creating the data label (which works better than a legend) took quite a few visits to that dialog box.
Jon Peltier says
Gary –
You could use my routine to Label Last Point for Excel 2007. Also, the way 2007 antialiases the magenta background makes it not completely disappear when it’s assigned as a transparent color.
Ducheznee says
While I absolutely agree that column/bar charts must start from 0, I’ve not considered the same argument for area charts (until you pointed it out here). Even at first glance I was not deceived by the Y-axis scale of Clarke’s chart – that is one of the many chart elements I take note of immediately. But perhaps that simply indicates that some of your past lessons are finally sinking into my skull.
Jon Peltier says
I honestly had not considered this requirement of area charts myself, until Mr Joyner pointed it out. And I started to think, it doesn’t matter. Then I realized that an area chart uses area to help encode the data. So it’s usually best to minimize opportunities to mislead your readers.
Unless that’s your objective, of course.
Andy Holaday says
My first impression was Jon’s line chart tells the story most clearly. I immediately understood Clarke’s “area chart” to be a line chart with shading fluff, but I had a harder time absorbing the interface between the light and the dark to gauge the measure of the trend. Possibly the slight change in the y-axis scale had something to do with my response. But, the y-axes in both of these charts span relevant values, which assuming the appropriate audience, should not be misinterpreted.
Kain’s chart is clearly meant to deceive (glad he chimed in). Mike mentioned the problem with the distortion here as well. Any trend can be flat-lined by exaggerating the value axis beyond reasonable limits.
Bob Gannon says
I think it would be more relevant to look at what percent of total federal tax revenues came from the top 1% of households and from each quintile.
Krish Swamy says
Great display of how putting a Min on the y-axis or setting a Max of 100% on the x-axis can give a misleading picture. It leads me to wonder what would have been right ways of showing this information.
Btw, I am not sure a line-graph does not produce the same misinterpretation. In several circles, line graphs, bar graphs and area plots are used interchangeably. People don’t necessarily pay attention to the fact that line graphs should be used mainly to depict time-series.
One possible Min could be the minimum tax rate in industrialized countries. It could be the min-rate in top 30 industrialized nations or the top 30 countries in terms of per capita GDP. This would set an effective baseline at the bottom end. How low would the tax rate need to go to match the lowest number available? The lowest based on OECD data from 2005 is about 18% in S Korea. New Zealand is about 20% as well.
And the max could then be the maximum rate of industrialized countries. The number that I get from the OECD survey is 45% in Germany. Now I am not sure whether this is a net tax rate (pretty sure it is not, seems too high) or a marginal tax rate on the highest incomes (45% seems too low).
So a range between about 15% to 45% with the appropriate reasoning provided for Mins and Maxes seems to be the right answer in this case.
Jon Peltier says
Matt –
I think the overriding factor is that cognitively our visual perception tells us the bars are showing length, because the bars start and end somewhere. Even “knowing” that it’s the top endpoints of the bars that encodes the values does not overcome what we see, which are the top and bottom endpoints of the bars, and the bars themselves between these endpoints.
Matt Cloves says
Jon,
Firstly, great site, please keep up the good work.
I really am very grateful for the time you put into passing on your insights.
I think this distinction between values encoded by their position, and values encoded by their length, is interesting.
(coming at this from a largely lay-person perspective)
While I appreciate that the presence of a ‘bar’ below the ‘top line’ of a bar in a bar chart could have assumed, or subconcious/implied(?) meaning, if we can assume that we are not using a stacked bar chart, and that all the points start on the same level, are we not effectivley looking at the ‘top line’ and its relative potision to other ‘top lines’? A kind of disconnected line chart. (ie. points encoded by their position)
Now, i’ll admit that if we were to lop off the bottom of a bar chart, and start some way up the axis, you would lose the ability to quickly gauge the changes between years (in this case), as they relate to each years totals (ie. did that loss of 3 represent a reduction of ~5%, or ~50%).
but do you not suffer the same loss in a line chart?
does this come down to one better method (bar) for comparing any year to any other, and one better method (line) for the trend over many years?
or is there some other aspect that is lost when you start a bar chart from half way, that isn’t such a factor with line charts.