This is the third of a five part series.
Quartiles for Box Plots
This topic is covered in the companion page Quartiles for Box Plots.
Hinge Techniques for Determining Quartiles
This topic is covered in the companion page Hinges.
Interpolation Methods of Determining Quartiles
As in the case of hinges, we need to consider four cases:
N = 4kN = 4k + 1N = 4k + 2N = 4k + 3
We will look at 8 (4k), 9 (4k+1), 10 (4k+2), and 11 (4k+3) values. Conceptually they are the same, but the simplified equations have differences.
We also need to look at three ways to distribute values along a number line. I’ll refer to these as the (N-1) Basis, the (N) Basis, and the (N+1) Basis. They are similar approaches, and give similar results.
N-1, N, and N+1 Bases for Computing Quartiles
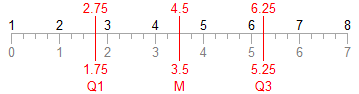
To make it easier to explain and comprehend the discussions that follow, the data sets will be laid out along a number line such as this:

The gray numbers under the number line correspond to locations along the length of the set of values (as a continuous variable), while numbers above the number line correspond to the index of a particular value of the data set. A fractional number above the number line indicates that the resulting value is interpolated between the adjacent values.
(N-1) Basis
The values are laid out on the integer positions of the number line, starting at zero and ending with N-1. The N values are distributed over a length of N-1. For N=8, it looks like this:

The position of a percentile p is that percentage of the length of the number line, or p*(n-1).
The N-1 Basis method is used by Excel’s legacy QUARTILE function and by the QUARTILE.INC function introduced in Excel 2010. It is apparently not used in any other calculation packages, though it is equivalent to at least one obscure quartile determination method not discussed here.
(N) Basis
Each value is located in the middle of a one-unit length of number line. Value 1 is located midway between 0 and 1, etc. The number line starts at zero and ends at N. The N values are distributed over a length of N. Again, for N=8:

The position of a percentile p is that percentage of the length of the number line, or p*(n).
The N Basis method is apparently not used by any package, even though it seems to me to be the most balanced method (while the others seem to have one kind of off-by-one error or the other).
(N+1) Basis
The values are laid out on the integer positions of the number line starting at 1 and ending at N. The number line extends beyond the first value to zero, and for symmetry beyond the Nth value to N+1. The values are then distributed over a length of N+1. For N=8:

The N+1 Basis is used by Minitab and JPM, and is available in SAS. It is also used in the QUARTILE.EXC function introduced in Excel 2010.
8 (4k) Values
The formulas for locating the quartiles on the number line for N=8(4k) using the N-1 Basis are shown here:
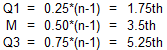
We need to increase the number line indices by 1 to get the value indices (or observation numbers).
These value indices are not the values of the quartiles. The value indices indicate which value is to be used as the quartile. A whole number M indicates that the Mth value is the quartile. A fractional number of the form M+m means the quartile is located between the Mth and (M+1)th values, the fraction m away from the Mth value.
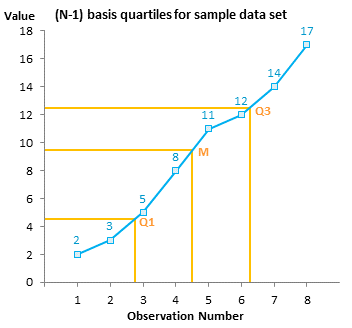
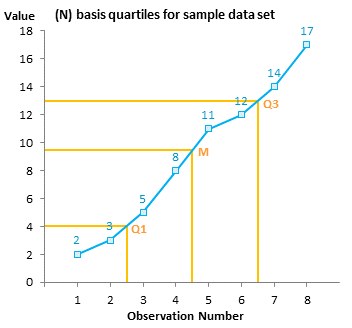
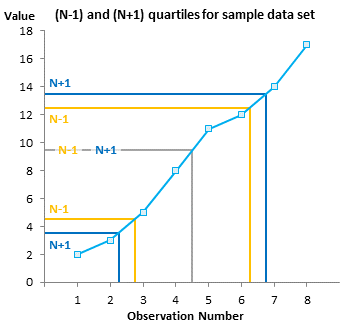
For example, let’s look at the 8-observation data set {2,3,5,8,11,12,14,17} in the chart below. For N=8 using the N-1 basis, our quartiles are the 2.75th, 4.5th, and 6.25th values. For the first quartile, 2.75 means the value 0.75 of the way from the 2nd to the 3rd values, or 0.75 of the way from 3 to 5, or 4.5. For the median, 4.5 means halfway between the 4th and 5th values, or halfway between 8 and 11, or 9.5. For the third quartile, 6.25 means the value 0.25 of the way from the 6th to the 7th value, or 0.25 of the way from 12 to 14, or 12.5.
Locate the quartiles on the number line for N=8(4k) using the N basis using these formulas:
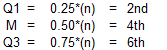
These number line indices must be incremented by 0.5 to get the value indices.
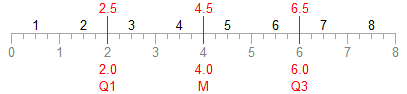
Looking at the 8-observation data set using the N basis, the quartiles are the 2.5th, 4.5th and 6.5th values, or 4, 9.5, and 13.
Finally, for N=8(4k) and the N+1 Basis, the number line indices are computed using:
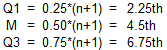
The number line indices correspond exactly to the value indices.
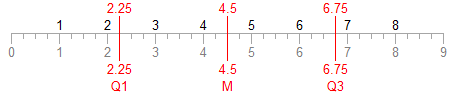
Looking at the 8-observation data set using the N+ basis, the quartiles are the 2.25th, 4.5th and 6.75th values, or 3.5, 9.5, and 13.5

The pattern you should notice is that while the medians are the same, the N-1 Basis quartiles are closer to the median than the N+1 Basis quartiles, and the N Basis quartiles are in between these. This chart compares the N-1 and N+1 Basis quartiles.
9 (4k+1) Values
Here are the formulas and number line representations for N=9 (4k+1) using the N-1 Basis:


Here are the formulas and number line representations for N=9 (4k+1) using the N Basis:


Here are the formulas and number line representations for N=9 (4k+1) using the N+1 Basis:


Same relative positions of the N-1, N, and N+1 Basis quartiles.
10 (4k+2) Values
It’s probably getting tedious, but here are the formulas and number line representations for N=10 (4k+2) using the N-1 Basis:

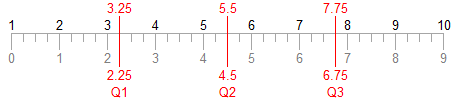
Here are the formulas and number line representations for N=10 (4k+2) using the N Basis:


Here are the formulas and number line representations for N=10(4k+2) using the N+1 Basis:
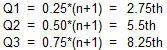

Same pattern as before, with the N-1 quartiles closest to the median and the N+1 quartiles furthest.
11 (4k+3) Values
Finally, here are the formulas and number line representations for N=11 (4k+3) using the N-1 Basis:
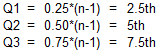

Here are the formulas and number line representations for N=11 (4k+3) using the N Basis:
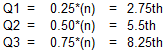

Here are the formulas and number line representations for N=11 (4k+3) using the N+1 Basis:


No deviation from the N-1, N, N+1 trends.
Comparison of Values from All Hinge and Quartile Methods
This topic is covered in the companion page Comparison.
Quartiles in the Peltier Tech Chart Utility
This topic is covered in the companion page Quartiles in the Peltier Tech Chart Utility.


derek says
Awesome, thanks very much for this, Jon. I haven’t got Excel 2010 yet, but I’m getting it very soon. Do these explanations generalize to the new PERCENTILE.INC and PERCENTILE.EXC functions in the same way? And will the new percentile functions work as general quantile functions as “well” as they did before?
Yes, a little secret of Excel PERCENTILE() was that it was–apparently–able to do terciles and octiles, etc., even though 100 doesn’t divide into 3 or 8. I say apparently because it’s not clear to me that it was doing a job of it that would satisfy statisticians. For instance, the “first tercile” was always between the 33rd and 34th percentile, but necessarily at the point between them that I would have expected.
derek says
Now I’ve had a chance to work with Excel 2010, can you help me understand the behavior of fractional percentiles? I’ve looked at the thirty-three-and-a-third percentile expecting it to usually be a simple linear interpolation of the 33rd and 34th percentiles (ie. the difference between the tercile and the 33%-ile should be a third of the difference between the 34%-ile and the 33%-ile). I find this to be true of both inclusive and exclusive percentiles when the number of data points is a multiple of three (n=3k), not true for inclusive percentiles for n=3k-1, and not true for exclusive percentiles for n=3k+1.
Is this right behavior for terciles? I’d like to be able to tell people that Excel has a fully-featured quantile function in disguise, but I can’t quite get the issues straight in my head.
derek says
Got it, obvious in hindsight. The reason the tercile “fails” in those circumstances is that it falls on an exact value, and therefore doesn’t need to be interpolated. the 33rd and 34th percentiles still need to be interpolated, but are interpolated with between the tercile and the data point before, or the tercile and the data point after, respectively, which is why the math stops working.
I can now feel confident that the percentile functions accurately allow for terciles, octiles, and indeed arbitrary quantiles: the p-th q-ile is calculated using the syntax
=PERCENTILE(,p/q)
derek says
angle brackets messed that expression up :-)
Jon Peltier says
Derek –
Not sure what your expression was supposed to be; WordPress ate what it couldn’t interpret.
You might check out the various .INC and .EXC stats functions added in Excel 2010. .INC is the same as Excel’s “inclusive” (N-1) legacy functions, and .EXC is the same as everyone else’s “exclusive” (N+1) functions. I don’t really know why anyone would pick either (N-1) or (N+1) over the other, or why they’d pick either of these over the N-basis calculations.
derek says
I’ll do it again:
=PERCENTILE(<range>,p/q)
gets you the pth q-ile of <range>, using Excel’s percentile function. It was using 2010’s INC and EXC functions together that finally made the behavior make sense for me: I’d noticed this potential use of Excel’s PERCENTILE function a few years ago, but couldn’t work out why it wasn’t doing what I thought it should do. Your great explanation, together with finally getting 2010, finally set my doubts to rest.
One reason why I might prefer N-1, inclusive, Excel’s traditional version, is that the zeroth and last quantiles are sensible numbers, the MIN and MAX of the range, as you would expect. Unpleasantly, but inevitably given the logic, the zeroth and ultimate quantiles of the N+1 version (and the N if Excel had it) are undefined: they throw a #NUM! error.
Jon Peltier says
Derek –
Sorry I lost your reply for a week. Too busy to keep up with everything.
Most of the sources that use N+1 based quantiles (I know of none that use the N-base, but I’m hardly an expert) have some kind of endpoint conditions that define the min or max when you get past the actual data endpoints. Excel may not have gotten that far yet…
DaleW says
The popular CDF quartiles are N-based quartiles, but with rounding (or hinging, if you prefer). The N base is very natural for describing sample statistics, but not as ideal for estimating population statistics. Adjusting the count by 1 degree of freedom — similar to the difference between STDEV() and STDEVP() — doesn’t quite work for quartiles. Instead an N+1/3 base has been recommended for quantiles as an approximate correction for population estimates.
The one advantage of Excel’s bizarre (N-1)-based interpolation quartiles is that there is no need to add endpoint conditions. Only for N-1 will exactly p=0 define the Minimum and exactly p=1 define the Maximum. The N or N+1 based interpolation quartiles have to include endpoint limits to avoid extrapolating beyond the available data, and possibly returning impossible values.
Jon Peltier says
The N-1 construction makes sense to me, if you think of the fencepost analogy. There are N fenceposts (values) with N-1 fence sections required to build a fence from the first to the last. Each post does not get an even amount of fence.
The N construction is like hanging a fence section by its middle from each post, so each post gets a whole fence section, but also so there is a half section extending beyond the endpoints. You need the end conditions to take these hanging sections into account. On the number line, each value has its equal length of the number line.
N+1 means there is a section of fence connecting each adjacent pair of posts, with a whole section on either side of the endpoints. The end conditions are even more elaborate than for N.
While N+1 is more common, the N and N-1 approaches a priori make more sense to this non-statistician.
DaleW says
Granted, ease of construction is a plus — and aligns well with John Tukey’s original exploratory intent for box and whisker plots (although Excel doesn’t use his original hinges).
Mathematical models have different constraints than fences. Models generally are supposed to model something out there in the real world. For box plots, that abstract something should be the population that we are sampling, no? That is why — if we care about optimizing this simple but robust modeling tool known as a box plot — each fencepost really does deserve an equal amount of fence, unless we have a good reason to make adjustments.
Clearly a small sample is unlikely to see 100% of the range of the actual underlying (continuous) population, yet that is exactly what Excel’s N-1 construction assumes. By contrast, N based models act as if our representative sample typically covers only fraction p=(N-1)/N — or using the number line, from fenceposts 0.5 to 7.5 step 1 if our sample size N=8 — which at least seems like an intuitive and plausible model. The (N+1) model leaves more margin at the edges — a degree of freedom lost in a way that a statistician might be able to explain for this alternate dispersion estimator — and in reality (at least by Monte Carlo simulation) for N=8 sample size, the mean sample range is 7/9-ths of the actual population range for a uniform distribution — exactly as that (N+1) Basis number line assumes!
This N+1 adjustment doesn’t work so cleanly with more typical populations that have peaks and tails, but my point today is that almost all credible quartiles or quantiles use a basis somewhere between N and N+1 (inclusive — but not in the quartile sense!). If you check the Wikipedia article on Quantiles, the first 5 of the 10 “R-types” are all N basis (the multiplier on p is N), with 4 of the remaining 5 using a larger than N basis. The Excel N-1 and the N+2 basis definitions would be Tukey outliers — by any of these definitions of quartiles.
Hien says
Thank you very much for your explaination. It is very useful for me.
Dan says
The web page isn’t displaying images, therefore I can’t see the equations and number lines. Is a shame as this is the first web page that looks like it might be able to give the answers I am looking for.
Jon Peltier says
Dan –
Thanks for letting me know. I have updated the images for this series of posts.