Recently Naomi Robbins, author of Creating More Effective Graphs
, and I discussed the difficulty of making Excel use appropriate axis tick spacing to chart binned data that has unequal bin widths. The example I’ll use here to describe the problem is taken from page 286 of Naomi’s book, under the heading Do not use equally spaced tick marks for uneven intervals on an arithmetic scale. I’ve optically digitized, that is, eyeballed, some data from her chart for the examples here.

Original Line Chart
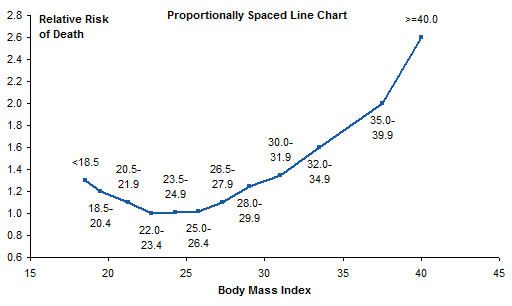
The original line chart looked very much like this, showing normalized mortality rates as a function of body mass index (BMI). This is how not to make your chart.
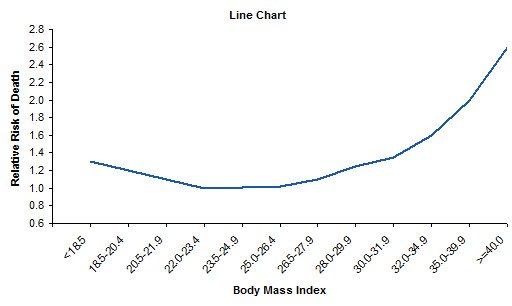
Data was reported as a single value for each range of BMI as in the table below.

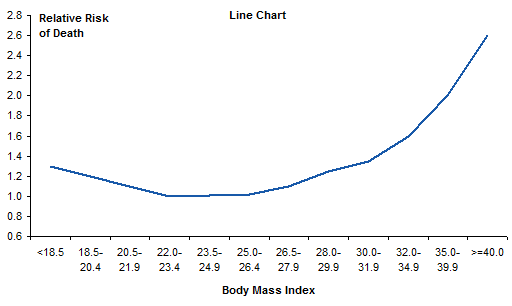
Improving the Line Chart
The first improvement we can make to the original chart is to rotate all labels into the horizontal orientation, so they are easier to read.
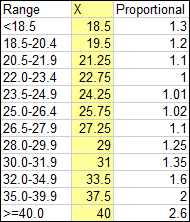
The next step is to change the horizontal spacing so that the separation between points is proportional to the difference in their X axis values. I’ve inserted the yellow column into the data, and in this column I’ve entered the midpoint of each bin range.
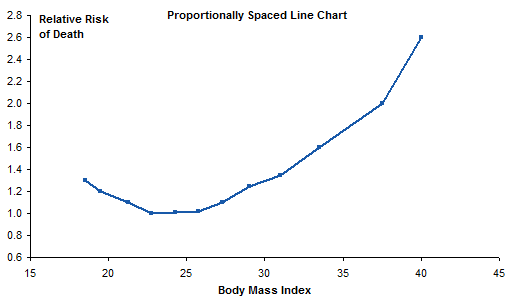
I plotted the mortality values against this new BMI column, and converted the chart to an XY Scatter chart so the new X values are recognized as numeric values and not equally spaced text labels. I added markers to show the actual points, but made the markers small so they aren’t emphasized with respect to the connecting lines.
Pretty good, but we have lost the bin range labels. No problem, let’s just add data labels to the series. You can add any type of labels (series name, Y values, whatever) and change the text of the labels manually, or you can use Rob Bovey’s Chart Labeler to do it automatically.
Yuck, that’s too cluttered. It was even worse when I initially had all labels below their respective points.
Let’s keep the points and their proportional spacing, but put the labels along the horizontal axis, as in the original chart. We can’t do that with built-in axis labels, but we can add a second series to the chart, with data labels. I added a column to hold the Y values for the added series; the Y values are equal to the axis minimum of 0.6.

Here I’ve highlighted the new series, and used the Chart Labeler (see link above) to add the labels below the points.

I’ve hidden the dummy series.
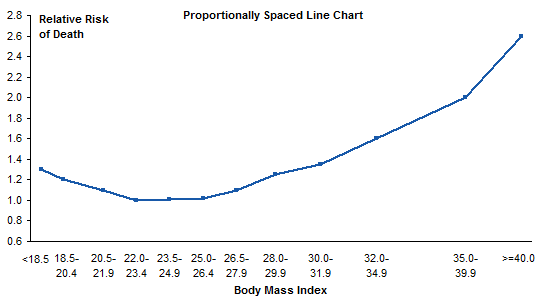
We’re still missing something: tick marks. Let’s add short vertical error bars to the dummy series. (See my article Custom Error Bars in Excel Charts for some helpful hints, and for a simply free utility I wrote to make it easier, even in Excel 2003 where it’s already pretty easy.) I placed a value in a cell, and used that cell as my custom error bar source range. My first value was way off, producing huge error bars. But by linking the error bars to the custom value in a cell, I made it easy to adjust the error bars until they looked appropriate, at a custom value of 0.04.

That’s quite an improvement over the original.
Alternative: Step Chart
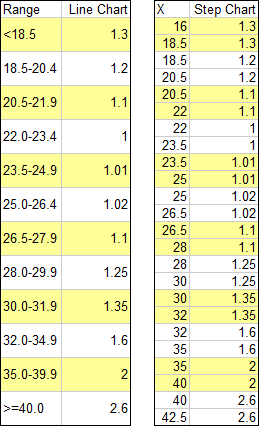
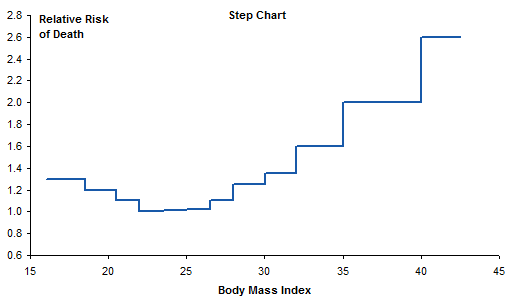
I decided to make a step chart, in which each horizontal line segment spans the bin range at the Y value for that bin. I split each data point from the original data into two points, one at either end of the bin range. I chose endpoints that extended a reasonable distance beyond their bin cutoffs.
And here’s the step chart. No need for bin range labels, because you can see where the bin edges are along the X axis. And it makes clear that each bin’s value is constant across the bin. Well, it isn’t really constant, but the way that the data was presented implies that it is.
Alternative: Histogram
Another variation is to make a histogram with variable width bins. Can’t do this with a column chart in Excel: all those columns have to be the same width. This chart was made with the original line chart data, which leads to equal width bins for unequal bin ranges. I did not make the common mistake of starting the vertical axis at the same minimum (0.6) that was suitable for the line charts.
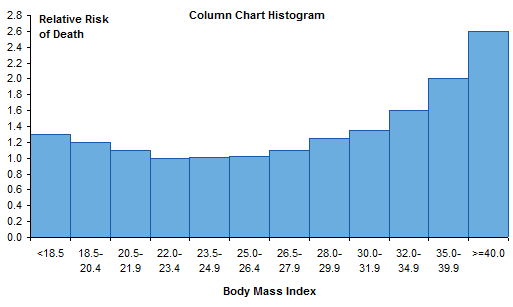
Instead of a column chart, we’ll use an XY chart and draw just the outlines of the columns. To do this we take the step chart data, and insert a row between each pair of duplicate X values. We copy in the X value from the cell above and assign a Y value of zero. This will produce a line from the end of one bin, straight down to the horizontal axis, then straight up to the start of the next bin.

Plot the data in an XY chart to get the pseudo-histogram. I left the endpoints at their Y values, not at zero, to indicate that these bins were not enclosed, but extended indefinitely. And again, I started the vertical axis at zero.
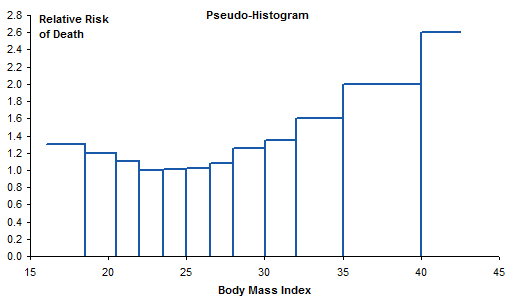
Summary
In her book, Naomi Robbins says Do not use equally spaced tick marks for uneven intervals on an arithmetic scale. Here I’ve demonstrated a few techniques to use proportionally spaced data points. Some are based on the “How Not To” line chart example in her book, and some are more intricate. Of all the options, I think I like the step chart best. It’s clean and uncluttered, and shows real values along both axes.


Calvin Graham says
I often find the question with a problem like this is “why were the spaces uneven to begin with?” Normally you’d expect the start/end bin sizes to be larger to accomodate outliers but there’s a lot of varience here for a planned survey/experiment
Bill McNair says
this tour de force of graphic representation is awesome. i like the x-y plot with x-axis labels as a series… but the pseudo-histogram is close behind.
one thing… BMI is so much more than the numbers. I would have included a picture such as the one from this link… http://www.healthyweightforum.org/eng/calculators/bmi-visual-graph/
thanks -bill
Bob says
Hi Jon,
Great post.
Lots to learn with the approaches shown here!
Cheers,
Bob
Jon Peltier says
Bill –
I didn’t get into it here, but BMI is really a poor way to characterize someone’s weight. You ideally should be measuring density, right? Body fat percentage? But BMI measures weight per area, not per volume, and it’s not really per area, but per height squared. No measure at all of width and thickness. Anyone who is at all active is off this curve. If someone does a little weight lifting, this curve and BMI in general is completely irrelevant. But BMI was latched onto years ago and we’re stuck with it.
derek says
Nice work. I’d go a step further and use a dummy series to replace the equally-spaced tick marks in your final graph with an unevenly-spaced set, where the numbers fall underneath the boundaries between columns.
BMI was invented by Adolpe Quetelet, the Belgian statistician and friend of Florence Nightingale (he also invented the sector area chart she famously used to illustrate Crimean War casualtires). You can see why he needed a transformation, because on the one hand he had access to large sets of weight statistics, but weight alone is not a measure of obesity. Fortunately he had corresponding sets of height data, but you can’t use weight/height either. Could he use height cubed? No, because people’s weights don’t go up in a population as the cube of height, but more like (height^3)^2/3.
(the 2/3 slope is empirical, it could just as easily be 3/5, or 0.69)
The bottom line is no individual person should ever be described as having “a BMI”, because BMI only makes sense, if it makes sense at all, as a comparative measure of whole populations, and you must take care that the populations have similar distributions of height, and similar numbers of keen weightlifters. One person alone can be a population of 100% weightlifters, and thus useless for comparison.
It goes double that no person should ever be taxed with having a BMI that’s “too high”. Any doctor who thinks his patient is in poor health has the tools and the subject available to determine that without recourse to tables of statistics.
Tom Rein says
I came across this post in a google search and it worked out perfectly for what I was doing! (Which had nothing to do with BMI, but with glass structures) Thanks for the great post!
Ciarán F says
Hei John, thanks for all your helpful tips!
I have one question (I haven’t managed to find an answer anywhere): How can you modify the y-axis for uneven increments, such as two different patterns? For example, take a y-axis split into 7 equal parts (by equal I mean equal in pixel-length), but with y-values of: 0, 5, 10, 15, 20, 30, 40, 50. Is this possible?
Thanks,
Ciarán
Jon Peltier says
Ciarán –
It’s possible to distort the axis scale like that, but it’s difficult to make it work, and it may confuse people trying to interpret the chart. I would advise not screwing up the scale.
Ciarán F says
Ok thanks Jon, it may not be worth all the hassle then, i’ll think of another way of presenting the data.
C